Last time I promised to write an entry about Data Augmentation and Dispersion however I lied. The basic problem is that in order to provide an example of either process I need to first talk about Markov chain Monte Carlo (MCMC) algorithms such as Gibbs sampling or Metropolis-Hastings Sampling. And if I am going to write about MCMC then there really is no reason not to write about reversible jump Markov chain Monte Carlo (rjMCMC).
And because I talk to much and as well as desire all of these post to more or less stand on their own we shall start by reviewing statistical inversion (parameter estimation). Forward and inverse problems may be broadly defined as data prediction and parameter estimation, respectively. That is, if the function 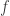
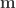


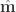

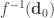
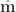
The most common sampling paradigm is Metropolis-Hasting (MH) sampling, which produces a random walk through the parameter space. The walk is conducted such that the long-run distribution of the steps converge to the target distribution, e.g., the PPD. Figure 1 shows an example of MH sampling for a one-dimensional target distribution; the distribution of the steps converge to the target as the sampling progresses.
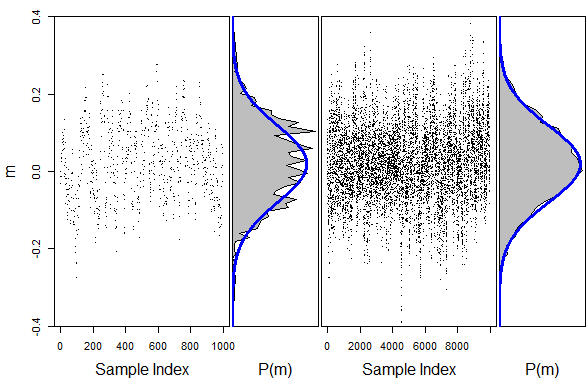
Figure 1: Samples (dots) and distribution for Metropolis-Hasting sampling after 1,000 (left) and 10,000 (right) iterations. The blue line indicates the target distribution and the shaded area is the sampled distribution.
The r code for this example is shown below; in summary the algorithm has 3 steps. These are draw the proposed model, accept or reject the proposed model, and save the model. Starting with the first step the proposed model 

![]()
where 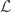


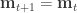

The rjMCMC is described after this code segment.
g.MCMC<-function(N= 10000)
{
# this stuff is to start the process
data = rnorm(100, mean=0, sd=1) # the simulated data mean forced to be
M = c(-Inf, 0) # starting model (log likelihood, m)
Q.mu1 = 0.05 # perterbation SD (chosen here to be bad for plotting !)
SAMPLES = M
# plot stuff
par(mar = c(0.1, 0.1, 0.1, 0.1) )
layout(mat = matrix(c(7,7,7,7,7,5,1,2,3,4,6,6,6,6,6), nrow=3, ncol=5, byrow=T),
widths = c(0.3, 1, 0.5, 1, 0.5), heights = c(0.05, 1, 0.2) )
M.frame = seq(-0.4, 0.4, length.out = 1001)
Target = dnorm(M.frame, mean= mean(data), sd=1/sqrt(length(data))) # the target distribution
# the prior
LB = -3
UB = 3
# the sampling
for (i in 1:N)
{
M.prime = M # Step 1 the proposal of a new model
M.prime[2] = M.prime[2] + rnorm(1, mean = 0, sd = Q.mu1) # the perterbation
# calculate the likelihood of the data
e = data – M.prime[2] # the residuals
LL = dnorm(e, mean=0, sd = 1, log = T ) # the log likelihood
M.prime[1] = sum(LL) # add LLs to get total log likelihood
# Step 2 MCMC acceptance
r = runif(1)
A = exp(M.prime[1]-M[1])
if (is.na(A)) {A= 0}
if ((A>=r)&(M.prime[2]>= LB)&(M.prime[2]<= UB))
{
M = M.prime
}
# Step 3 record sample
SAMPLES = rbind(SAMPLES, M)
rownames(SAMPLES) = NULL
if (i == 1000)
{
SAMPLES=SAMPLES[1:1000,]
# plot PPD
plot(1:1000,SAMPLES[,2], pch=”.”, yaxs=”i”, ylim=c(-0.4, 0.4), xlab=”Sample Index”, ylab=”m”)
axis(1, at = 500, tick = F, label = “Sample Index”, cex.axis=1.5, mgp=c(3, 3, 0))
axis(2, at = 0, tick = F, label = “m”, cex.axis=1.5, mgp=c(3, 3, 0))
H=hist(SAMPLES[,2], breaks=seq(min(SAMPLES[,2]),max(SAMPLES[,2]), length.out=51), plot=F)
plot( seq(0, 1.04*max(H$den), length.out=length(H$mids)),H$mids, type=”n”, xaxs=”i”, ylab=””,
xlab=””, yaxs=”i”, yaxt=”n”, xaxt=”n”, ylim=c(-0.4, 0.4))
axis(1, at = mean( seq(0, 1.04*max(H$den), length.out=length(H$mids))), tick = F, label = “P(m)”, cex.axis=1.5, mgp=c(3, 3, 0))
polygon( c(0, H$den, 0), c(-0.4, H$mids, 0.4), col=”grey”)
lines( Target, M.frame, col=”blue”, lwd=3)
}
if (i == N)
{
# plot PPD
plot(1:N,SAMPLES[,2], pch=”.”, yaxs=”i”, ylim=c(-0.4, 0.4), xlab=”Sample Index”, ylab=”m”, yaxt=”n”)
axis(1, at = N/2, tick = F, label = “Sample Index”, cex.axis=1.5, mgp=c(3, 3, 0))
H=hist(SAMPLES[,2], breaks=seq(min(SAMPLES[,2]),max(SAMPLES[,2]), length.out=51), plot=F)
plot( seq(0, 1.04*max(H$den), length.out=length(H$mids)),H$mids, type=”n”, xaxs=”i”, ylab=””,
xlab=””, yaxs=”i”, yaxt=”n”, xaxt=”n”, ylim=c(-0.4, 0.4))
axis(1, at = mean( seq(0, 1.04*max(H$den), length.out=length(H$mids))), tick = F, label = “P(m)”, cex.axis=1.5, mgp=c(3, 3, 0))
polygon( c(0, H$den, 0), c(-0.4, H$mids, 0.4), col=”grey”)
lines( Target, M.frame, col=”blue”, lwd=3)
}
}
}
g.MCMC()
So far we have only considered cases where the number of parameters is known(i.e., the dimension of the PPD fixed), however in many setting the number of parameters is not know a priori. In such cases it may be possible to calculate the evidence for each model and select the best one, but in common applications situation that can be computationally impractical. In addition even if it is possible the point estimate for the dimension of the PPD will have uncertainty that will not be accounted for in the parameter estimate uncertainties! The rjMCMC algorithm solves both these problems. The PPD is expanded to span multiple dimensions (numbers of parameters). Like the MCMC algorithm rjMCMC takes a random walk though the parameter space but now the walk can not only perturb the parameter values but “Birth” and “Death” sets if parameters. The rjMCMC acceptance probability is
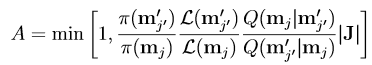 .
.
The time subscript (t) has been suppressed for clarity. The subscript 


The proposal distributions will operate in pares as the reverse move for a perturbation must be a perturbation, a birth must pare with a death, and a death with a birth. Also, in general the prior ratio will change only by the prior of the birthed / deathed parameters. Thus if the birthed parameters are proposed from the prior The acceptance probability becomes that of the standard MCMC.
To illustrate the rjMCMC algorithm consider the following regression example. It conists of regressing 20 y’s onto 20 x’s. The order of the model is unknown, i.e., it could be a constant, linear, or quadratic. The data and true model (linear) is shown in the next figure.

The simulated noisy (circles) and true (blue line) data used inthe rjMCMC example.
The posterior uncertainty of the parameters is shown in the histograms below. Note the PPD might be under-sampled but i wanted the code to run relatively quickly and I do not want my out put to look different from your s when you run it! Out of the 25000 samples models 7595 had only a constant, 17376 had a mean and linear trend and only 28 had a quadratic term! the code for this is below.

The posterior marginal uncertainties of beta0, beta1, and beta2, the regression parameters. The dashed vertical blue lines indicate the “true” values.
To recap Bayesians commonly approximate the PPD with samples. These samples can be gathered by MCMC type algorithms. It is possible to collect the samples even if the number of model parameters are unknown. And the rjMCMC algorithm selects parameters from models proportionally to their evidence. Finally parameter uncertainties account for model selection uncertainties!
Tune in next time for Bayesian BI! Also I recently moved to Hothead games so check out our products if you get a chance (Boom Boom Soccer and Boom Boom Foot Ball are in soft launch so please play them and leave any comments you have!)
P.S. I have noticed that this blog format changes some of the symbols in the code if you have trouble running it leave a comment and I will email you directly.
The rjMCMC code:
g.predict<-function(Mod, X)
{
j = Mod[2]
beta0 = Mod[3]
beta1 = Mod[4]
beta2 = Mod[5]
P = 0*X + beta0
if (j >= 2) {P = P + X*beta1}
if (j >= 3) {P = P + (X^2)*beta2}
return(P)
}
g.perterb<-function(M=c(-Inf, 3, 0, 0, 0), Qsd=c(0, 0, 0.1, 0.01, 0.001), LB = c(0, 1, -10, -2, -1 ), UB = c(0, 1, 10, 2, 1 ) , data=data.frame(1:100, rnorm(100)))
{
# unpacking hte parameters
LL = M[1]
j = M[2]
#beta0 = M[3]
#beta1 = M[4]
#beta2 = M[5]
x = data[,1]
y = data[,2]
ORDER = sample(3:(3+j-1), j)
for (i in ORDER)
{
M.prime = M # make the proposal model
M.prime[i] = M.prime[i] + rnorm(1, mean = 0, sd= Qsd[i]) # add random noise to old model
P = g.predict(M.prime, x) # get predicted values
LL.prime = sum(dnorm(y-P, mean= 0, sd=1, log=T)) # compute loglikihood
M.prime[1] = LL.prime # save LL
r = runif(1) # random uniform
MH = exp(LL.prime – LL) # Metropolis-hasting acceptance probability value
if ((r <= MH) & (M.prime[i] >= LB[i]) & (M.prime[i] <= UB[i]) ) {M = M.prime} # if accepted and in bounds
}
return(M)
}
g.birth<-function(M=c(-Inf, 1, 0, 0, 0), Qsd=c(0, 0, 0.1, 0.01, 0.001), LB = c(0, 1, -10, -2, -1 ), UB = c(0, 1, 10, 2, 1 ) , data=data.frame(1:100, rnorm(100)))
{
# unpacking hte parameters
LL = M[1]
j = M[2]
x = data[,1]
y = data[,2]
if (j == 1)
{
M.prime = M # make the proposal model
M.prime[2] = 2
M.prime[4] = runif(1, min = LB[4], max = UB[4]) # propose from prior
P = g.predict(M.prime, x) # get predicted values
LL.prime = sum(dnorm(y-P, mean= 0, sd=1, log=T)) # compute loglikihood
M.prime[1] = LL.prime # save LL
r = runif(1) # random uniform
MH = exp(LL.prime – LL) # Metropolis-hasting acceptance probability value
if (r <= MH) {M = M.prime} # if accepted
}
if (j == 2)
{
M.prime = M # make the proposal model
M.prime[2] = 3
M.prime[5] = runif(1, min = LB[5], max = UB[5]) # propose from prior
P = g.predict(M.prime, x) # get predicted values
LL.prime = sum(dnorm(y-P, mean= 0, sd=1, log=T)) # compute loglikihood
M.prime[1] = LL.prime # save LL
r = runif(1) # random uniform
MH = exp(LL.prime – LL) # Metropolis-hasting acceptance probability value
if (r <= MH) {M = M.prime} # if accepted
}
return(M)
}
g.death<-function(M=c(-Inf, 2, 1, 0.5, 0.0), Qsd=c(0, 0, 0.1, 0.01, 0.001), LB = c(0, 1, -10, -2, -1 ), UB = c(0, 1, 10, 2, 1 ) , data=data.frame(1:100, rnorm(100)))
{
# unpacking hte parameters
LL = M[1]
j = M[2]
x = data[,1]
y = data[,2]
if (j == 3)
{
M.prime = M # make the proposal model
M.prime[2] = 2
M.prime[5] = 0 # propose from prior
P = g.predict(M.prime, x) # kill the parameter
LL.prime = sum(dnorm(y-P, mean= 0, sd=1, log=T)) # compute loglikihood
M.prime[1] = LL.prime # save LL
r = runif(1) # random uniform
MH = exp(LL.prime – LL) # Metropolis-hasting acceptance probability value
if (r <= MH) {M = M.prime} # if accepted
}
if (j == 2)
{
M.prime = M # make the proposal model
M.prime[2] = 1
M.prime[4] = 0 # kill the parameter
P = g.predict(M.prime, x) # get p
LL.prime = sum(dnorm(y-P, mean= 0, sd=1, log=T)) # compute loglikihood
M.prime[1] = LL.prime # save LL
r = runif(1) # random uniform
MH = exp(LL.prime – LL) # Metropolis-hasting acceptance probability value
if (r <= MH) {M = M.prime} # if accepted
}
return(M)
}
}
g.explore<-function(old, d)
{
Qsd. = c(0, 0, 0.1, 0.01, 0.001)
LB. = c(0, 1, -10, -2, -1 )
UB. = c(0, 1, 10, 2, 1 )
move.type = sample(1:3, 1) # the type of move i.e., perterb, birth, death
if (move.type == 1) {old = g.perterb(M=old, Qsd =Qsd., LB = LB., UB=UB., data= d)}
if (move.type == 2) {old = g.birth(M=old, Qsd =Qsd., LB = LB., UB=UB., data = d)}
if (move.type == 3) {old = g.death(M=old, Qsd =Qsd., LB = LB., UB=UB., data = d )}
return(old)
}
g.rjMCMC<-function(Ndat = 100, Nsamp = 25000, BURN = 1000)
{
#+ (1:Ndat)*0.75
beta0 = 3
beta1 = 0.1
beta2 = 0
data = data.frame(x = 1:Ndat, y = beta0 +rnorm(Ndat)+ (1:Ndat)*beta1 ) # the simulated data
x11(height=4, width = 5)
plot(data[,1], data[,2], xlab=”x”, ylab=”y”, main = “Simulated Data”)
lines(1:Ndat,beta0 + (1:Ndat)*beta1, col=”blue”, lwd=3 )
points(data[,1], data[,2])
Mod.old = c(-Inf, 1, 4, 0, 0)
for(i in 1:BURN) # the burn in
{
Mod.old = g.explore(old = Mod.old, d = data)
}
print(Mod.old)
REC = Mod.old
for(i in 1:(Nsamp-1)) # the burn in
{
Mod.old = g.explore(old = Mod.old, d = data)
REC = rbind(REC, Mod.old)
rownames(REC) = NULL
}
print(table(REC[,2]))
x11(height=4, width = 8)
x = 16
par(mar = c(4,4,1,1), oma = c(1,1,1,1))
layout(mat = matrix(c(1, 2, 3), nrow=1, ncol=3, byrow=T) )
REC = rbind(REC, c(0, 3, 0,0,0)) # just to make the ploting easier
H1 = hist(REC[,3],breaks = seq(-10, 10, length.out = 1001), plot=F)
H2 = hist(REC[REC[,2] >= 2 ,4], breaks = seq(-2, 2, length.out = 1001), plot=F)
H3 = hist(REC[REC[,2] >= 3 ,5], breaks = seq(-1, 1, length.out = 1001), plot=F)
plot(H1$mids, H1$den, type=”n”, xlab=”Beta 0″, ylab= “P(Beta 0)”,xaxs=”i”, yaxs=”i”)
polygon(x=c(H1$mids[1], H1$mids, H1$mids[length(H1$mids)] ), y=c(0, H1$den, 0), col=”grey”, border=F )
abline( v = beta0, col=”blue”, lwd=2, lty=2 )
plot(H2$mids, H2$den, type=”n”, xlab=”Beta 1″, ylab= “P(Beta 1)”,xaxs=”i”, yaxs=”i”)
polygon(x=c(H2$mids[1], H2$mids, H2$mids[length(H2$mids)] ), y=c(0, H2$den, 0), col=”grey”, border=F )
abline( v = beta1, col=”blue”, lwd=2, lty=2 )
plot(H3$mids, H3$den, type=”n”, xlab=”Beta 2″, ylab= “P(Beta 2)”,xaxs=”i”, yaxs=”i”)
polygon(x=c(H3$mids[1], H3$mids, H3$mids[length(H3$mids)] ), y=c(0, H3$den, 0), col=”grey”, border=F )
abline( v = beta2, col=”blue”, lwd=2, lty=2 )
}
g.rjMCMC(Ndat = 20)
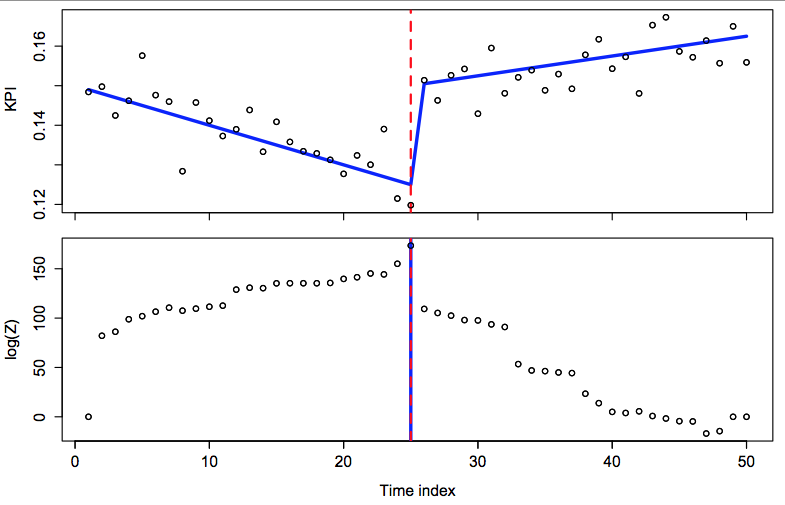
 ) onto the time/ index of the observation and other relevant factors. The change points are represented by the
) onto the time/ index of the observation and other relevant factors. The change points are represented by the  . So for example a linear model with no change point that might have design matrix
. So for example a linear model with no change point that might have design matrix
 th and
th and  st KPI measures could have design matrix
st KPI measures could have design matrix
 where
where 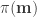 , to its posterior probability density (PPD),
, to its posterior probability density (PPD),  , by the introduction of data information via the likelihood function,
, by the introduction of data information via the likelihood function, 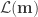 . Using Bayes’ rule, the PPD can be expressed as
. Using Bayes’ rule, the PPD can be expressed as  ,where
,where  is the Bayesian evidence. As the PPD is a distribution and therefor normalized
is the Bayesian evidence. As the PPD is a distribution and therefor normalized  (Now that I am out of grad school I can write internals the way that makes sense, none of this
(Now that I am out of grad school I can write internals the way that makes sense, none of this 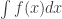 non-sense. You don’t agree?, then riddle me why derivatives don’t act like brackets? ). Thus
non-sense. You don’t agree?, then riddle me why derivatives don’t act like brackets? ). Thus 
 and
and  , as a function of the data space (schematically compressed into one dimension). Model
, as a function of the data space (schematically compressed into one dimension). Model 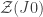 is more widely distributed than
is more widely distributed than 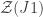 . Evidence compares the two models at the observed data (represented by the vertical line). In this example,
. Evidence compares the two models at the observed data (represented by the vertical line). In this example,  [i.e.,
[i.e., 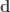 ~ Norm(
~ Norm( 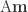 ,
, ![\int d{\bf m} (2\pi)^{-k/2}|\text{C}|^{-1/2} \exp(-\frac{1}{2}[{\bf d}-\text{A}{\bf m}]^{t}\text{C}^{-1}[{\bf d}-\text{A}{\bf m}])](https://s0.wp.com/latex.php?latex=%5Cint+d%7B%5Cbf+m%7D+%282%5Cpi%29%5E%7B-k%2F2%7D%7C%5Ctext%7BC%7D%7C%5E%7B-1%2F2%7D+%5Cexp%28-%5Cfrac%7B1%7D%7B2%7D%5B%7B%5Cbf+d%7D-%5Ctext%7BA%7D%7B%5Cbf+m%7D%5D%5E%7Bt%7D%5Ctext%7BC%7D%5E%7B-1%7D%5B%7B%5Cbf+d%7D-%5Ctext%7BA%7D%7B%5Cbf+m%7D%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) which by
which by ![( 2 \pi )^{(j-k)/2}| \text{C}|^{-1/2}|\text{A}^t\text{C}^{-1}\text{A}|^{-1/2} \exp (-\frac{1}{2}[{\bf d}^t \text{C}^{-1}{\bf d} - {\bf d}^t \text{C}^{-1} \text{A} (\text{A}^t \text{C}^{-1} \text{A} )^{-1}\text{A}^t \text{C}^{-1} {\bf d} ] )](https://s0.wp.com/latex.php?latex=%28+2+%5Cpi+%29%5E%7B%28j-k%29%2F2%7D%7C+%5Ctext%7BC%7D%7C%5E%7B-1%2F2%7D%7C%5Ctext%7BA%7D%5Et%5Ctext%7BC%7D%5E%7B-1%7D%5Ctext%7BA%7D%7C%5E%7B-1%2F2%7D+%5Cexp+%28-%5Cfrac%7B1%7D%7B2%7D%5B%7B%5Cbf+d%7D%5Et+%5Ctext%7BC%7D%5E%7B-1%7D%7B%5Cbf+d%7D+-+%7B%5Cbf+d%7D%5Et+%5Ctext%7BC%7D%5E%7B-1%7D+%5Ctext%7BA%7D+%28%5Ctext%7BA%7D%5Et+%5Ctext%7BC%7D%5E%7B-1%7D+%5Ctext%7BA%7D+%29%5E%7B-1%7D%5Ctext%7BA%7D%5Et+%5Ctext%7BC%7D%5E%7B-1%7D+%7B%5Cbf+d%7D+%5D+%29&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where 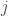 is the dimension of
is the dimension of 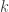 is the dimension of
is the dimension of