
Hi all
This post shows how to use SQL to get estimates of the expected event times given either the Exponential or Weibull distributions and right censored data. That might seem like a strange restriction however it is very powerful have estimates in a query instead of requiring R as they can be used directly in dashboard (in my experience with Tableau). Also if like me you are lazy being able to just have a query that answers your question is much nicer then having to analyze data from a query.
Before showing the query it might be helpful to describe what is being queried. Starting with the exponential distribution. Let 


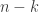
![\mathcal{L}(\lambda) = \prod f_x (x= d_i)^{\delta_i} [1- F_x (x = d_j)]^{1- \delta_i} = \prod f_x (x= d_i)^{\delta_i} [S_x (x = d_j)]^{1- \delta_i}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%28%5Clambda%29+%3D+%5Cprod+f_x+%28x%3D+d_i%29%5E%7B%5Cdelta_i%7D+%5B1-+F_x+%28x+%3D+d_j%29%5D%5E%7B1-+%5Cdelta_i%7D+%3D+%5Cprod+f_x+%28x%3D+d_i%29%5E%7B%5Cdelta_i%7D+%5BS_x+%28x+%3D+d_j%29%5D%5E%7B1-+%5Cdelta_i%7D+&bg=ffffff&fg=333333&s=0&c=20201002)

![\mathcal{L}(\lambda) = \prod \lambda^{\delta_i} \exp( - \lambda d_i \delta_i) \exp( - \lambda d_i [1- \delta_i] ) = \lambda^{\sum_{i = 1}^{n} \delta_i} exp( - \lambda \sum_{i = 1}^{n} d_i)](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%28%5Clambda%29+%3D+%5Cprod+%5Clambda%5E%7B%5Cdelta_i%7D+%5Cexp%28+-+%5Clambda%C2%A0+d_i+%5Cdelta_i%29%C2%A0+%5Cexp%28+-+%5Clambda+d_i+%5B1-+%5Cdelta_i%5D+%29+%3D+%5Clambda%5E%7B%5Csum_%7Bi+%3D+1%7D%5E%7Bn%7D+%5Cdelta_i%7D+exp%28+-+%5Clambda+%5Csum_%7Bi+%3D+1%7D%5E%7Bn%7D+d_i%29&bg=ffffff&fg=333333&s=0&c=20201002)



For the Weibull distribution this a bit more complicated! Recall that the pdf ofr a Weibull is 

![\mathcal{L}(\lambda, \gamma) = \prod [\lambda \gamma {d_i}^{\gamma-1}]^{\delta_i} \exp(- \lambda {d_i}^{\gamma-1})](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%28%5Clambda%2C+%5Cgamma%29+%3D+%5Cprod+%5B%5Clambda+%5Cgamma+%7Bd_i%7D%5E%7B%5Cgamma-1%7D%5D%5E%7B%5Cdelta_i%7D+%5Cexp%28-+%5Clambda+%7Bd_i%7D%5E%7B%5Cgamma-1%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)

![\log \mathcal{L}(\lambda, \gamma) = \sum \delta_i \log [\lambda \gamma {d_i}] + (\gamma -1) \sum \delta_i \log(d_i) - \lambda \sum {d_i}^{\gamma}](https://s0.wp.com/latex.php?latex=%5Clog+%5Cmathcal%7BL%7D%28%5Clambda%2C+%5Cgamma%29+%3D+%5Csum+%5Cdelta_i+%5Clog+%5B%5Clambda+%5Cgamma+%7Bd_i%7D%5D+%2B+%28%5Cgamma+-1%29+%5Csum+%5Cdelta_i+%5Clog%28d_i%29+-+%5Clambda+%5Csum+%7Bd_i%7D%5E%7B%5Cgamma%7D&bg=ffffff&fg=333333&s=0&c=20201002)


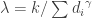
The value of 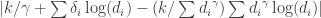
So this whole post comes down to how can a SQL query find the optimal value of
This query assume there is a table with user ids, event times and user ages. The cent follows the same structure as the churn posts query.
SELECT age, gamma,lambda, n, r, o_f ,lambda_ex
FROM
(
SELECT age, gamma, n, r,lambda, o_f, lambda_ex,
row_number() over (partition by age order by o_f) as index
FROM
(
SELECT age, gamma, n, r, r/(SUM_U_to_gamma + SUM_t_to_gamma) as lambda, r/(SUM_U + SUM_t) as lambda_ex,
ABS(r/gamma + SUM_log_t - (r/ (SUM_U_to_gamma + SUM_t_to_gamma) )*(SUM_U_to_gamma_log_u + SUM_t_to_gamma_log_t)) as o_f
FROM
(
SELECT age, gamma,
sum(1) as n,
SUM(event) as r,
SUM(CASE WHEN event = 0 THEN (event_time::float) END) as SUM_U,
SUM(CASE WHEN event = 1 THEN (event_time::float) END) as SUM_t,
SUM(CASE WHEN event = 0 THEN (event_time::float)^gamma END) as SUM_U_to_gamma,
SUM(CASE WHEN event = 1 THEN (event_time::float)^gamma END) as SUM_t_to_gamma,
SUM(CASE WHEN event = 0 THEN ln(event_time::Float) END) as SUM_log_U,
SUM(CASE WHEN event = 1 THEN ln(event_time::Float) END) as SUM_log_t,
SUM(CASE WHEN event = 0 THEN ln(event_time::float)*event_time^gamma END) as SUM_U_to_gamma_log_u,
SUM(CASE WHEN event = 1 THEN ln(event_time::float)*event_time^gamma END) as SUM_t_to_gamma_log_t
FROM
(
(SELECT id, CASE WHEN next_time is null then 0 else 1 end as event,
datediff('sec', clean_time, coalesce(next_time,'2017-08-28 00:00:00') ) as event_time, age, 1 as key
FROM
(SELECT id, clean_time, age,
max(clean_time) over (partition by id order by clean_time rows between 1 following and 1 following) as next_time,
row_number() over (partition by id,age order by random() ) as index
FROM tab_event
and clean_time <= '2017-08-28 00:00:00'
)
where index <= 1
and age <= 7) Q1
LEFT JOIN
(SELECT random() as gamma, 1 as key
from tab_event
LIMIT 10000 ) Q2
ON Q1.key = Q2.key
)
where event_time > 0
GROUP BY 1,2
)
)
)
where index = 1
ORDER BY 1,2
That is it for now tune in next time for more survival analysis!

Pingback: An introduction or “vulgurization” on Churn | Bayesian Business Intelligence
SELECT *
FROM
(
SELECT active_on_date, power(ln(2),1/gamma)*power(lambda,(-1/gamma)) as MEDIAN_RET_TIME, log(2)/lambda_ex as MEDIAN_RET_TIME2, max(ACTIVE_ON_DATE) OVER () as MAX_DAY
FROM
(
SELECT active_on_date, gamma,lambda, n, r, o_f ,lambda_ex
FROM
(
SELECT active_on_date, gamma, n, r,lambda, o_f, lambda_ex,
row_number() over (partition by active_on_date order by o_f) as index
FROM
(
SELECT active_on_date, gamma, n, r, r/(SUM_U_to_gamma + SUM_t_to_gamma) as lambda, r/(SUM_U + SUM_t) as lambda_ex,
ABS(r/gamma + SUM_log_t – (r/ (SUM_U_to_gamma + SUM_t_to_gamma) )*(SUM_U_to_gamma_log_u + SUM_t_to_gamma_log_t)) as o_f
FROM
(
SELECT active_on_date, gamma,
sum(1) as n,
SUM(event) as r,
SUM(CASE WHEN event = 0 THEN (event_time) END) as SUM_U,
SUM(CASE WHEN event = 1 THEN (event_time) END) as SUM_t,
SUM(CASE WHEN event = 0 THEN power(event_time,gamma) END) as SUM_U_to_gamma,
SUM(CASE WHEN event = 1 THEN power(event_time,gamma) END) as SUM_t_to_gamma,
SUM(CASE WHEN event = 0 THEN ln(event_time) END) as SUM_log_U,
SUM(CASE WHEN event = 1 THEN ln(event_time) END) as SUM_log_t,
SUM(CASE WHEN event = 0 THEN ln(event_time)*power(event_time, gamma) END) as SUM_U_to_gamma_log_u,
SUM(CASE WHEN event = 1 THEN ln(event_time)*power(event_time, gamma) END) as SUM_t_to_gamma_log_t
FROM
(
(SELECT player_id, CASE WHEN next_age is null then 0 else 1 end as event,
COALESCE(next_age, age_possible) – age as event_time, active_on_date, 1 as key
FROM
(SELECT Q1.*, age_possible
FROM
(
(SELECT player_id, active_on_date, age,
max(age) over (partition by player_id order by age rows between 1 following and 1 following) as next_age,
row_number() over (partition by player_id, active_on_date order by rand() ) as index
FROM datapipe.cohort
where active_on_date >= ‘2018-12-06’) Q1
LEFT JOIN
(SELECT player_id, age_possible
FROM datapipe.user_summary) Q2
ON Q1.player_id = Q2.player_id
)
)
where index 0
GROUP BY 1,2
)
)
)
where index = 1
)
)
WHERE abs(DATETIME_DIFF(MAX_DAY, ACTIVE_ON_DATE, DAY)) >= 7
ORDER BY 1,2
LikeLike