
Hi all
This post discuses a couple of strategies for estimating the weights (training) of a neural network (NN). Both strategies are based on down sampling the data ($latex {\bf d}). Both strategies make analogy with annealing; i.e., ignoring some of the observations makes the objective function flatter and thus easier to traverse. This is sort of equivalent to racing the likelihood to a power of 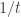
![\phi({\bf w})= \log ( \Pi_{i=1}^{N} P[d_i|{\bf w}])](https://s0.wp.com/latex.php?latex=%5Cphi%28%7B%5Cbf+w%7D%29%3D+%5Clog+%28+%5CPi_%7Bi%3D1%7D%5E%7BN%7D+P%5Bd_i%7C%7B%5Cbf+w%7D%5D%29+&bg=ffffff&fg=333333&s=0&c=20201002)
![\phi({\bf w})^{1/t} \approx \log ( \Pi_{i \text{ in } S} P[d_i|{\bf w}])](https://s0.wp.com/latex.php?latex=%5Cphi%28%7B%5Cbf+w%7D%29%5E%7B1%2Ft%7D+%5Capprox+%5Clog+%28+%5CPi_%7Bi+%5Ctext%7B+in+%7D+S%7D+P%5Bd_i%7C%7B%5Cbf+w%7D%5D%29+&bg=ffffff&fg=333333&s=0&c=20201002)


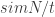
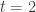
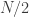
Before going into the details I would like to highlight that neither of these worked particularly well. In general, a solution of similar quality could be found faster (fewer forward computations) just by using all the data, the backwards propagation with random jitter of my earlier post, and starting a few times (at different random locations), then taking the best result. This might mean that my test problem is too simple (a global optimal is easy to find so there is not need to explore the whole space) or the methods them selves are just bad.
The first method I am calling batched annealing. Here the data (

index_rand = random_order(1:n) # randomly sort data
d_star = d[index_rand]
A_star = A[index_rand]
For i in 1:n # loop over observations
d_temp = d_star[1:i] # down sample the data
A_temp = A_star[1:i, ] # down sample the
W_old = train_NN(d_temp, A_temp, W_old)
What I found doing this was that very often I would get two sets of data that could not both be fit; which ever one got more members into the training set first would be fit and the other set would “ignored” / poorly fit. The issue is that if fitting one set resulted in a better (either by hold out error / or just likelihood / misfit of data) solution it would not find that solution if the other set had its data added first.
The second method is batched tempering (at least I am good at coming up with names for these methods…) is an analogy to parallel tempering. Again data are excluded to mimic higher temperatures. This is a bit more complex than the first methods. Instead of one optimizer there are 
In true parallel tempering individual Markov chains (which are analogous to the optimizers used here) equivalent optimizers swap with randomly chosen partners. Here because there is no requirement to make the process ergodic I simply order the optimizers using a weighted random order. Note that it is very important not to just force the optimizers into a deterministic / strict ordering; doing so will stop the best chains from having an opportunity to explore around their space.
The code is appended relative to the previous posts on NNs the only really important part is the “g.sto” function. In sudo code
for ( i in 1:N) # loop over the number of steps you want to optimize the function
for (j in 1:num_opt) # loop through each of the optimizers
W_old = record[j] # get previous model for optimizer j
index_rand = random_samp(sample_from = 1:n, size = NS[j] ) # randomly sample data NS is a list of sizes
d_temp = d[index_rand] # get the down sampled data
A_temp = A[index_rand] # get the down sampled sensitivity matrix
W_temp = train_NN(d_temp, A_temp, maxit = 1000) # train the NN for 1000 iterations on the subset of data
phi_all_temp = objective_function_NN(d, A, W_temp) # evaluate the model with all data
record = record_udate(W_temp, phi_all_temp) # record the model
record = order(record)
That is really it for now. Sorry this is more or a reminder than a description.
Tune in next time for more adventures in analytics.
g.logit <-function(x)
{
return(1/(1+exp(-x)))
}
g.pred <-function(w, A, d)
{
zeta21 = w[1]*A[,1] + w[ 2]*A[,2] +w[ 3]*A[,3] +w[ 4]*A[,4] +w[ 5]*A[,5] +w[ 6]*A[,6] +w[ 7]*A[,7] +w[ 8]*A[,8] + w[9]
zeta22 = w[10]*A[,1] + w[11]*A[,2] +w[12]*A[,3] +w[13]*A[,4] +w[14]*A[,5] +w[15]*A[,6] +w[16]*A[,7] +w[17]*A[,8] +w[18]
zeta23 = w[19]*A[,1] + w[20]*A[,2] +w[21]*A[,3] +w[22]*A[,4] +w[23]*A[,5] +w[24]*A[,6] +w[25]*A[,7] +w[26]*A[,8] +w[27]
zeta24 = w[28]*A[,1] + w[29]*A[,2] +w[30]*A[,3] +w[31]*A[,4] +w[32]*A[,5] +w[33]*A[,6] +w[34]*A[,7] +w[35]*A[,8] +w[36]
sigma21 = g.logit(zeta21)
sigma22 = g.logit(zeta22)
sigma23 = g.logit(zeta23)
sigma24 = g.logit(zeta24)
zeta31 = w[37]*sigma21+w[38]*sigma22+w[39]*sigma23 +w[40]*sigma24 +w[41]
zeta32 = w[42]*sigma21+w[43]*sigma22+w[44]*sigma23 +w[45]*sigma24 +w[46]
sigma31 = g.logit(zeta31)
sigma32 = g.logit(zeta32)
zeta41 = w[47]*sigma31+w[48]*sigma32 +w[49]
sigma41 =g.logit(zeta41)
return(sigma41)
}
g.phy <-function(w, A, d)
{
sigma41 = g.pred(w, A, d)
#phy = 0.5*sum((d-sigma41)^2)
phy = -2*sum( d* log(sigma41) + (1-d)*log(1-sigma41) ) # + sum(w^2)/nrow(A) # the penalty for size
return(phy)
}
g.phy.prime <-function(w, A, d)
{
# get the grad vecter
num.obs = nrow(A)
zeta21 = w[1]*A[,1] + w[ 2]*A[,2] +w[ 3]*A[,3] +w[ 4]*A[,4] +w[ 5]*A[,5] +w[ 6]*A[,6] +w[ 7]*A[,7] +w[ 8]*A[,8] + w[9]
zeta22 = w[10]*A[,1] + w[11]*A[,2] +w[12]*A[,3] +w[13]*A[,4] +w[14]*A[,5] +w[15]*A[,6] +w[16]*A[,7] +w[17]*A[,8] +w[18]
zeta23 = w[19]*A[,1] + w[20]*A[,2] +w[21]*A[,3] +w[22]*A[,4] +w[23]*A[,5] +w[24]*A[,6] +w[25]*A[,7] +w[26]*A[,8] +w[27]
zeta24 = w[28]*A[,1] + w[29]*A[,2] +w[30]*A[,3] +w[31]*A[,4] +w[32]*A[,5] +w[33]*A[,6] +w[34]*A[,7] +w[35]*A[,8] +w[36]
sigma21 = g.logit(zeta21)
sigma22 = g.logit(zeta22)
sigma23 = g.logit(zeta23)
sigma24 = g.logit(zeta24)
zeta31 = w[37]*sigma21+w[38]*sigma22+w[39]*sigma23 +w[40]*sigma24 +w[41]
zeta32 = w[42]*sigma21+w[43]*sigma22+w[44]*sigma23 +w[45]*sigma24 +w[46]
sigma31 = g.logit(zeta31)
sigma32 = g.logit(zeta32)
zeta41 = w[47]*sigma31+w[48]*sigma32 +w[49]
sigma41 =g.logit(zeta41)
#gradphy = (sigma41 - d)
gradphy = -2* ((d/sigma41) - (1-d)/(1-sigma41))
grad41 = sigma41*(1-sigma41)
grad31 = sigma31*(1-sigma31)
grad32 = sigma32*(1-sigma32)
grad21 = sigma21*(1-sigma21)
grad22 = sigma22*(1-sigma22)
grad23 = sigma23*(1-sigma23)
grad24 = sigma24*(1-sigma24)
gradmat = cbind( (grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21*A[,1], # + 2*w[ 1]/num.obs ,
(grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21*A[,2], # + 2*w[ 2]/num.obs ,
(grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21*A[,3], # + 2*w[ 3]/num.obs ,
(grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21*A[,4], # + 2*w[ 4]/num.obs ,
(grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21*A[,5], # + 2*w[ 5]/num.obs ,
(grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21*A[,6], # + 2*w[ 6]/num.obs ,
(grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21*A[,7], # + 2*w[ 7]/num.obs ,
(grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21*A[,8], # + 2*w[ 8]/num.obs ,
(grad32*w[48]*w[42] + grad31*w[47]*w[37])*gradphy*grad41*grad21 , # + 2*w[ 9]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22*A[,1], # + 2*w[10]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22*A[,2], # + 2*w[11]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22*A[,3], # + 2*w[12]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22*A[,4], # + 2*w[13]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22*A[,5], # + 2*w[14]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22*A[,6], # + 2*w[15]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22*A[,7], # + 2*w[16]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22*A[,8], # + 2*w[17]/num.obs ,
(grad32*w[48]*w[43] + grad31*w[47]*w[38])*gradphy*grad41*grad22 , # + 2*w[18]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23*A[,1], # + 2*w[19]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23*A[,2], # + 2*w[20]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23*A[,3], # + 2*w[21]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23*A[,4], # + 2*w[22]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23*A[,5], # + 2*w[23]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23*A[,6], # + 2*w[24]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23*A[,7], # + 2*w[25]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23*A[,8], # + 2*w[26]/num.obs ,
(grad32*w[48]*w[44] + grad31*w[47]*w[39])*gradphy*grad41*grad23 , # + 2*w[27]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24*A[,1], # + 2*w[28]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24*A[,2], # + 2*w[29]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24*A[,3], # + 2*w[30]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24*A[,4], # + 2*w[31]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24*A[,5], # + 2*w[32]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24*A[,6], # + 2*w[33]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24*A[,7], # + 2*w[34]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24*A[,8], # + 2*w[35]/num.obs ,
(grad32*w[48]*w[45] + grad31*w[47]*w[40])*gradphy*grad41*grad24 , # + 2*w[36]/num.obs ,
w[47]*gradphy*grad41*grad31*sigma21 , # + 2*w[37]/num.obs ,
w[47]*gradphy*grad41*grad31*sigma22 , # + 2*w[38]/num.obs ,
w[47]*gradphy*grad41*grad31*sigma23 , # + 2*w[39]/num.obs ,
w[47]*gradphy*grad41*grad31*sigma24 , # + 2*w[40]/num.obs ,
w[47]*gradphy*grad41*grad31 , # + 2*w[41]/num.obs , # 5
w[48]*gradphy*grad41*grad32*sigma21 , # + 2*w[42]/num.obs ,
w[48]*gradphy*grad41*grad32*sigma22 , # + 2*w[43]/num.obs ,
w[48]*gradphy*grad41*grad32*sigma23 , # + 2*w[44]/num.obs ,
w[48]*gradphy*grad41*grad32*sigma24 , # + 2*w[45]/num.obs ,
w[48]*gradphy*grad41*grad32 , # + 2*w[46]/num.obs , # 5
gradphy*grad41*sigma31 , # + 2*w[47]/num.obs ,
gradphy*grad41*sigma32 , # + 2*w[48]/num.obs ,
gradphy*grad41 # + 2*w[49]/num.obs # 3
)
#print(gradmat)
grad = apply(gradmat, 2, sum )
return(grad)
}
NNplot<-function(w = w.old)
{
plot(1:4, 1:4, type="n", xlab= "", ylab="", ylim=c(0,9), xlim=c(0,5), xaxt="n", yaxt="n")
w = 10*w/max(abs(w))
g.col = rep("blue", 49)
g.col[w < 0] = "red"
#print(w[1:8])
segments(x0=1, x1=2, y0=1, y1 = 3, lwd=abs(w[1]), col=g.col[1])
segments(x0=1, x1=2, y0=2, y1 = 3, lwd=abs(w[2]), col=g.col[2])
segments(x0=1, x1=2, y0=3, y1 = 3, lwd=abs(w[3]), col=g.col[3])
segments(x0=1, x1=2, y0=4, y1 = 3, lwd=abs(w[4]), col=g.col[4])
segments(x0=1, x1=2, y0=5, y1 = 3, lwd=abs(w[5]), col=g.col[5])
segments(x0=1, x1=2, y0=6, y1 = 3, lwd=abs(w[6]), col=g.col[6])
segments(x0=1, x1=2, y0=7, y1 = 3, lwd=abs(w[7]), col=g.col[7])
segments(x0=1, x1=2, y0=8, y1 = 3, lwd=abs(w[8]), col=g.col[8])
segments(x0=1, x1=2, y0=1, y1 = 4, lwd=abs(w[10]), col=g.col[10])
segments(x0=1, x1=2, y0=2, y1 = 4, lwd=abs(w[11]), col=g.col[11])
segments(x0=1, x1=2, y0=3, y1 = 4, lwd=abs(w[12]), col=g.col[12])
segments(x0=1, x1=2, y0=4, y1 = 4, lwd=abs(w[13]), col=g.col[13])
segments(x0=1, x1=2, y0=5, y1 = 4, lwd=abs(w[14]), col=g.col[14])
segments(x0=1, x1=2, y0=6, y1 = 4, lwd=abs(w[15]), col=g.col[15])
segments(x0=1, x1=2, y0=7, y1 = 4, lwd=abs(w[16]), col=g.col[16])
segments(x0=1, x1=2, y0=8, y1 = 4, lwd=abs(w[17]), col=g.col[17])
segments(x0=1, x1=2, y0=1, y1 = 5, lwd=abs(w[19]), col=g.col[19])
segments(x0=1, x1=2, y0=2, y1 = 5, lwd=abs(w[20]), col=g.col[20])
segments(x0=1, x1=2, y0=3, y1 = 5, lwd=abs(w[21]), col=g.col[21])
segments(x0=1, x1=2, y0=4, y1 = 5, lwd=abs(w[22]), col=g.col[22])
segments(x0=1, x1=2, y0=5, y1 = 5, lwd=abs(w[23]), col=g.col[23])
segments(x0=1, x1=2, y0=6, y1 = 5, lwd=abs(w[24]), col=g.col[24])
segments(x0=1, x1=2, y0=7, y1 = 5, lwd=abs(w[25]), col=g.col[25])
segments(x0=1, x1=2, y0=8, y1 = 5, lwd=abs(w[26]), col=g.col[26])
segments(x0=1, x1=2, y0=1, y1 = 6, lwd=abs(w[28]), col=g.col[28])
segments(x0=1, x1=2, y0=2, y1 = 6, lwd=abs(w[29]), col=g.col[29])
segments(x0=1, x1=2, y0=3, y1 = 6, lwd=abs(w[30]), col=g.col[30])
segments(x0=1, x1=2, y0=4, y1 = 6, lwd=abs(w[31]), col=g.col[31])
segments(x0=1, x1=2, y0=5, y1 = 6, lwd=abs(w[32]), col=g.col[32])
segments(x0=1, x1=2, y0=6, y1 = 6, lwd=abs(w[33]), col=g.col[33])
segments(x0=1, x1=2, y0=7, y1 = 6, lwd=abs(w[34]), col=g.col[34])
segments(x0=1, x1=2, y0=8, y1 = 6, lwd=abs(w[35]), col=g.col[35])
segments(x0=2, x1=3, y0=3, y1 = 4, lwd=abs(w[37]), col=g.col[37])
segments(x0=2, x1=3, y0=4, y1 = 4, lwd=abs(w[38]), col=g.col[38])
segments(x0=2, x1=3, y0=5, y1 = 4, lwd=abs(w[39]), col=g.col[39])
segments(x0=2, x1=3, y0=6, y1 = 4, lwd=abs(w[40]), col=g.col[40])
segments(x0=2, x1=3, y0=3, y1 = 5, lwd=abs(w[42]), col=g.col[42])
segments(x0=2, x1=3, y0=4, y1 = 5, lwd=abs(w[43]), col=g.col[43])
segments(x0=2, x1=3, y0=5, y1 = 5, lwd=abs(w[44]), col=g.col[44])
segments(x0=2, x1=3, y0=6, y1 = 5, lwd=abs(w[45]), col=g.col[45])
segments(x0=3, x1=4, y0=4, y1 = 4.5, lwd=abs(w[47]), col=g.col[47])
segments(x0=3, x1=4, y0=5, y1 = 4.5, lwd=abs(w[48]), col=g.col[48])
symbols(x=1, y=1, circles=0.5 , add=T, inches = .25, bg ="grey")
symbols(x=1, y=2, circles=0.5 , add=T, inches = .25, bg ="grey")
symbols(x=1, y=3, circles=0.5 , add=T, inches = .25, bg ="grey")
symbols(x=1, y=4, circles=0.5 , add=T, inches = .25, bg ="grey")
symbols(x=1, y=5, circles=0.5 , add=T, inches = .25, bg ="grey")
symbols(x=1, y=6, circles=0.5 , add=T, inches = .25, bg ="grey")
symbols(x=1, y=7, circles=0.5 , add=T, inches = .25, bg ="grey")
symbols(x=1, y=8, circles=0.5 , add=T, inches = .25, bg ="grey")
text(x=rep(1,8), y= 1:8, labels = c("Not", "And", "or", "Xor", "contra", "IfThen", "alpha", "beta") )
symbols(x=2, y=3, circles=0.5 , add=T, inches = .20, bg ="grey")
symbols(x=2, y=4, circles=0.5 , add=T, inches = .20, bg ="grey")
symbols(x=2, y=5, circles=0.5 , add=T, inches = .20, bg ="grey")
symbols(x=2, y=6, circles=0.5 , add=T, inches = .20, bg ="grey")
symbols(x=3, y=4, circles=0.5 , add=T, inches = .20, bg ="grey")
symbols(x=3, y=5, circles=0.5 , add=T, inches = .20, bg ="grey")
symbols(x=4, y=4.5, circles=0.5 , add=T, inches = .20, bg ="grey")
}
NN2 <-function(w = (runif(49)-0.5)*10 , A=A., d=d., N= 10000, mod = 1, t = 100, ME = 0.0001,verb = 0 )
{
PP = 0.01
eta = 1
ND = nrow(A)
#print(w)
phy = g.phy(w, A,d)
#print(phy)
rec = c(phy, w)
phy.best = phy
w.best = w
fm = 0
phy.last = phy
i.last = 1
w.last = w
for ( i in 1:N)
{
phy = g.phy(w, A, d)
# get the grad vecter
grad = g.phy.prime(w, A, d)
#update the weights
if (mod == 6 )
{
eta = 0.5
r = runif(1)
if( r <= 0.01) { mag.w = sqrt(sum(w*w)) j = rnorm(49, sd = mag.w /sqrt(49))/5 } if( r > 0.01)
{
mag.grad = sqrt(sum(grad*grad))
j = rnorm(49, sd = mag.grad /sqrt(49))/5
}
#print(sqrt(sum(j*j)))
w.new = w-eta*(grad+j)
#new misfit
phy.new = g.phy(w.new, A,d)
}
phy.new = g.phy(w.new, A,d)
if(is.nan(phy.new) )
{
phy.new = Inf
}
k = 0
fm = fm + 1
#if(verb == 1)
#{
#print(phy)
#print(phy.new)
#}
#print(phy.new > phy )
TEST = ( phy.new > phy )
if(is.na(TEST)) {TEST = FALSE}
while( ( TEST ) & ( k <= 100 ) )
{
#if(verb == 1)
#{
#print("---------------------- in the while loop ----------------------")
#print(phy)
#print(phy.new)
#print(k)
#}
# normal back prop step shrink
if (mod == 6 )
{
#print("here")
eta = eta/2
r = runif(1)
if( r <= 0.1) { mag.w = sqrt(sum(w*w)) j = rnorm(49, sd = mag.w /sqrt(49)) } if( r > 0.1)
{
mag.grad = sqrt(sum(grad*grad))
j = rnorm(49, sd = mag.grad /sqrt(49))
}
#j = rnorm(49, sd = 1)
w.new = w-eta*(grad+j)
#new misfit
phy.new = g.phy(w.new, A,d)
fm = fm + 1
}
k = k+ 1
#if(k == 50)
# {print("k==50!")}
if(is.nan(phy.new) )
{
phy.new = Inf
}
if(phy < phy.best) { phy.best = phy w.best = w } TEST = ( phy.new > phy )
if(is.na(TEST)) {TEST = FALSE}
}
if(phy.new < phy)
{
phy = phy.new
w = w.new
}
# add the model to the
rec = rbind(rec, c(phy,w) )
rownames(rec) = NULL
sigma41 = g.pred(w, A, d)
r = runif(1)
if (r <= PP) { PP= PP/2 ND.40 = min(c(ND, 40)) #if ( verb == 1) # { # print(paste(i, "of", N, "(=", i/N,") and", fm, "forward models")) # print(paste("# Obs.", ND) ) # print(phy) # print(paste("log phy best = ", log(phy.best) )) # print(paste("max abs error", max(abs(d-sigma41))) ) # print(paste("max abs error", max(abs(d[1:ND.40]-sigma41[1:ND.40]))) ) # } ## ##print( data.frame(A[1:ND.40,], value= d[1:ND.40], pred = round(sigma41[1:ND.40], 4), error = round(abs(d[1:ND.40] -sigma41[1:ND.40] ),4) )) #if ( log(phy.last) - log(phy) >= 0.5 )
# {
# x11()
par(mfrow=c(2,1), mar=c(4,4,1,1))
NNplot(w.last)
plot( log(rec[1:i.last,1] ), pch=".", xlab = "Index", ylab = "Phy")
# }
phy.last = phy
w.last = w
i.last = i
}
if( (max(abs(d-sigma41)) <= ME ) & (i >= 10 ) ) # & (i >= 1000)
{
if ( verb == 1)
{
ND.40 = min(c(ND, 40))
sigma41 = g.pred(w, A, d)
print(paste(i, "of", N, "(=", i/N,") and", fm, "forward models"))
print(paste("# Obs.", ND) )
print(phy)
print(paste("log phy best = ", log(phy.best) ))
print(paste("max abs error", max(abs(d-sigma41))) )
print(paste("max abs error", max(abs(d[1:ND.40]-sigma41[1:ND.40]))) )
}
par(mfrow=c(2,1), mar=c(4,4,1,1))
NNplot(w.last)
plot( log(rec[1:i.last,1] ), pch=".", xlab = "Index", ylab = "Phy")
return(c(1,phy , w))
}
}
if ( verb == 1)
{
ND.40 = min(c(ND, 40))
sigma41 = g.pred(w, A, d)
print(paste(i, "of", N, "(=", i/N,") and", fm, "forward models"))
print(paste("# Obs.", ND) )
print(phy)
print(paste("log phy best = ", log(phy.best) ))
print(paste("max abs error", max(abs(d-sigma41))) )
print(paste("max abs error", max(abs(d[1:ND.40]-sigma41[1:ND.40]))) )
}
return(c(0,phy,w))
}
g.sto<-function( ME. = 0.01)
{
A.= matrix(c(0, 1,0,0,0,0, 1, 1,
0, 1,0,0,0,0, 0, 1,
0, 1,0,0,0,0, 1, 0,
0, 1,0,0,0,0, 0, 0,
0, 0,1,0,0,0, 1, 1,
0, 0,1,0,0,0, 0, 1,
0, 0,1,0,0,0, 1, 0,
0, 0,1,0,0,0, 0, 0,
0, 0,0,1,0,0, 1, 1,
0, 0,0,1,0,0, 0, 1,
0, 0,0,1,0,0, 1, 0,
0, 0,0,1,0,0, 0, 0,
0, 0,0,0,1,0, 1, 1,
0, 0,0,0,1,0, 0, 1,
0, 0,0,0,1,0, 1, 0,
0, 0,0,0,1,0, 0, 0,
0, 0,0,0,0,1, 1, 1,
0, 0,0,0,0,1, 0, 1,
0, 0,0,0,0,1, 1, 0,
0, 0,0,0,0,1, 0, 0,
1, 1,0,0,0,0, 1, 1,
1, 1,0,0,0,0, 0, 1,
1, 1,0,0,0,0, 1, 0,
1, 1,0,0,0,0, 0, 0,
1, 0,1,0,0,0, 1, 1,
1, 0,1,0,0,0, 0, 1,
1, 0,1,0,0,0, 1, 0,
1, 0,1,0,0,0, 0, 0,
1, 0,0,1,0,0, 1, 1,
1, 0,0,1,0,0, 0, 1,
1, 0,0,1,0,0, 1, 0,
1, 0,0,1,0,0, 0, 0,
1, 0,0,0,1,0, 1, 1,
1, 0,0,0,1,0, 0, 1,
1, 0,0,0,1,0, 1, 0,
1, 0,0,0,1,0, 0, 0,
1, 0,0,0,0,1, 1, 1,
1, 0,0,0,0,1, 0, 1,
1, 0,0,0,0,1, 1, 0,
1, 0,0,0,0,1, 0, 0)
, nrow=40, ncol=8, byrow=T)
colnames(A.) = c("Not", "And", "or", "Xor", "contra", "IfThen", "alpha", "beta")
A.=rbind(A.,
A. + (runif(320)-0.5)*0.5,
A. + (runif(320)-0.5)*0.5,
A. + (runif(320)-0.5)*0.5,
A. + (runif(320)-0.5)*0.5,
A. + (runif(320)-0.5)*0.5,
A. + (runif(320)-0.5)*0.5,
A. + (runif(320)-0.5)*0.5,
A. + (runif(320)-0.5)*0.5,
A. + (runif(320)-0.5)*0.5
)
d. = matrix(c(1,0,0,0, 1,1,1,0, 0,1,1,0, 1,0,1,1, 1,1,0,1,
0,1,1,1, 0,0,0,1, 1,0,0,1, 0,1,0,0, 0,0,1,0), nrow= 40, ncol=1 )
d. = rbind(d., d., d., d., d.,
d., d., d., d.,
d.)
N = nrow(A.)
NC = 40
NS = floor(seq(0, N, length.out = (NC+1)))[2:(NC+1)]
# make the intial data sets
DS = list()
for ( i in 1:NC)
{
DS[[i]] = sort(sample(1:N, NS[i]))
}
Ws.all = list()
Ws.sub = list()
for ( i in 1:NC)
{
Ws.sub[[i]] = c(0, Inf, rnorm(49))
# c(-8.08041439 , 2.06346497 , -1.54031571 , -2.88445872 , 6.47911272 , -8.49851364 , -7.15282381 , -7.68137939 , 11.59349865 , -11.86608750 , 1.99563545 , -2.98180221 , 10.13098873 , -6.46718542 , 4.07691956 , 6.02385674 , -7.61151232 , 7.61163996 , -3.35555794 , 0.03171125 , -1.51265323 , 1.08372308 , 0.74957913 , -2.19298751 , -1.24309429 , -4.29052458 , 5.43952098 , -1.52537648 , 4.59789938 , 1.61840032 , 1.20710391 , -2.13490775 , -1.63754937 , -3.15367652 , -2.95884757 , 1.42927769 , -17.70410965 , -6.64222147 , 8.18730908 , -11.45157253 , 24.59673331 , -18.76273941 , -14.44924125 , 20.51598107 , -17.67475199 , 6.38152918 , 33.44444894 , -35.86176580 , -14.85993747))
Ws.all[[i]] = Ws.sub[[i]]
}
MBL = 100
BLI = 0
while ( (Ws.all[[NC]][1] == 0) & (BLI <= MBL) )
{
print("-------------------------------------------------------------")
print(BLI)
BLI = BLI +1
for( i in 1:NC)
{
w.temp = Ws.sub[[i]][3:51]
SAMP.temp = DS[[i]]
w.temp = NN2(w= w.temp, N= 500, A= A.[SAMP.temp,], d = d.[SAMP.temp,], mod = 6, t = 100, ME = 0.1 , verb = 0 )
#w.temp = NN2(w= w.temp, N= 100, A= A., d = d., mod = 6, t = 100, ME = 0.05 , verb = 0 )
Ws.sub[[i]] = w.temp
#print("------------------- pre sort ------------------")
#print(NS[[i]])
#print(Ws.sub[[i]][1:5])
#print(i)
}
phys = 1:NC
for( i in 1:NC)
{
w.temp = Ws.sub[[i]][3:51]
v. = 0
if(i ==NC) {v. = 1}
w.temp = NN2(w= w.temp, N= 10, A= A., d = d., mod = 6, t = 100, ME = 0.1 , verb = v. )
Ws.sub[[i]] = w.temp
phys[i] = w.temp[2]
}
#print(phys)
probs = -0.5*phys
#print(probs)
probs = ( probs - min(probs) )
#print(probs)
probs = exp(10*probs/max(probs))
#print(probs)
NI = rev(sample(1:NC, prob = probs))
#for( i in 1:NC)
# {
# print("------------------- pre sort ------------------")
# print(NS[[i]])
# print(Ws.sub[[i]][1:5])
# print(i)
# }
print(
data.frame(true.order = order(sapply(Ws.sub, function(x) x[2], simplify=TRUE), decreasing=TRUE) ,
probs_true = probs[ order(sapply(Ws.sub, function(x) x[2], simplify=TRUE), decreasing=TRUE)],
phy = phys[ order(sapply(Ws.sub, function(x) x[2], simplify=TRUE), decreasing=TRUE)],
rand.order = NI, probs = probs[NI] )
)
#Ws.sub = Ws.sub[order(sapply(Ws.sub, function(x) x[2], simplify=TRUE), decreasing=TRUE)]
Ws.sub.temp = Ws.sub
for( i in 1:NC)
{
Ws.sub[i] = Ws.sub.temp[NI[i]]
}
best.index = order(sapply(Ws.sub, function(x) x[2], simplify=TRUE), decreasing=TRUE)[NC]
for ( i in 1:NC)
{
DS[[i]] = sort(sample(1:N, NS[i]))
r = runif(1)
if( (i <= NC/2) )
{
if( (r<= 0.45) & (r >=0) ) {Ws.sub[[i]] = Ws.sub[[best.index]]}
if( (r<= 0.5) & (r >=0.45) ) {Ws.sub[[i]] = c(0, Inf, rnorm(49)) }
}
}
print("Model with full data ")
print(Ws.sub[[best.index]])
}
w.old = Ws.sub[[NC]]
return(w.old)
}
w.old = g.sto( )
